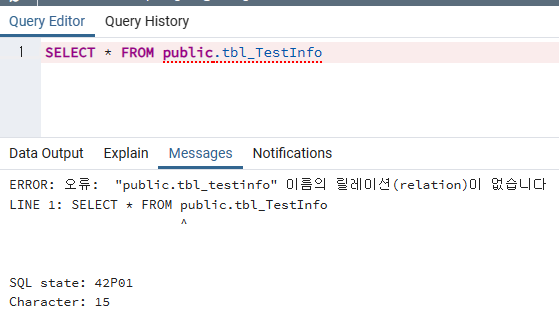
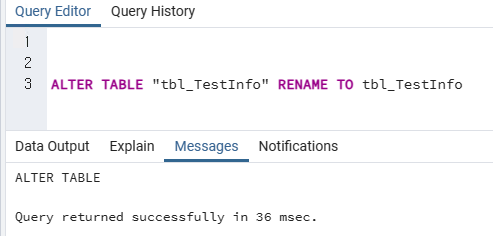
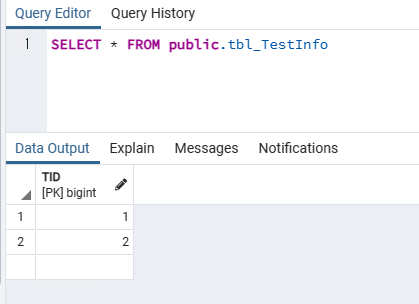
//중복된데이터 검색
//컬럼명 : nClientID, nModelID, nAlgType
//테이블 : MuraExceptCondition
select nClientID, nModelID, nAlgType, COUNT(*) AS CNT
from tbl_MuraExceptCondition
GROUP BY nClientID, nModelID, nAlgType
HAVING COUNT(*) > 1
//삭제
--SELECT COUNT(*)
--from tbl_MuraExceptCondition
DELETE tbl_MuraExceptCondition
WHERE nIndex NOT IN (
SELECT MAX(nIndex)
from tbl_MuraExceptCondition
GROUP BY nClientID, nModelID, nAlgType
)
//퍼온것
실제 작업시에는 대부분 unique index를 걸거나, primary key 를 걸어 놓아 그런 일이 벌어지지 않지만, 벌크로 데이터를 작업하거나 할 경우, 중복된 데이터를 보거나, 제거하고 싶을 때가 있습니다.
단순히 중복 카운트를 조회 하고 싶을 경우엔, 다음과 같이 grouping 하고 count를 세면 됩니다만,
테이블 명 : tbl_some_table
컬럼 명: some_id, some_nm, some_description
-- 중복 카운트
SELECT some_id, COUNT(*)
FROM tbl_some_table
GROUP BY some_id
HAVING COUNT(*) > 1;
-- 여러 컬럼의 중복 카운트
SELECT some_id, some_nm, some_description, COUNT(*)
FROM tbl_some_table
GROUP BY some_id, some_nm, some_description
HAVING COUNT(*) > 1; |
중복된 데이터 중, 첫번째(또는 마지막) 하나만 빼고 나머지를 조회한다거나, 삭제하고 싶을 때가 있습니다. 그러한 경우 다음과 같은 inline view 로 처리할 수 있습니다. (WITH 를 사용해도 되나, 하위 버전의 SQL 일 경우에는 WITH 구문이 먹지 않죠. 응? 하위 버전은 ROW_NUMBER 가 안 먹겠네요. 아이고 배야. - 하위 버전도 inline view 를 여럿 쓰면 되긴 합니다만.)
-- 중복 데이터를 알고 싶다.
SELECT *
FROM (
SELECT some_id
, dup_idx = ROW_NUMBER() OVER (
PARTITION BY some_id ORDER BY some_id )
FROM tbl_some_table (NOLOCK)
) tb_dup
WHERE tb_dup.dup_idx > 1;
-- 중복 데이터 기준으로 중복된 데이터를 다 조회하고 싶다.
SELECT t.*
FROM (
SELECT some_id , dup_idx = ROW_NUMBER() OVER (
PARTITION BY some_id ORDER BY some_id )
FROM tbl_some_table (NOLOCK)
) tb_dup INNER JOIN tbl_some_table t (NOLOCK)
ON t.some_id = tb_dup.some_id
WHERE tb_dup.dup_idx > 1;
-- 중복 데이터를 지우고 싶다!!!
DELETE tb_dup
FROM (
SELECT some_id ,
dup_idx = ROW_NUMBER() OVER (
PARTITION BY some_id ORDER BY some_id )
FROM tbl_some_table
) tb_dup
WHERE tb_dup.dup_idx > 1;
-- 여러 컬럼일 경우? 중복 데이터를 지우고 싶다!!!
DELETE tb_dup
FROM (
SELECT some_id, some_nm, some_description ,
dup_idx = ROW_NUMBER() OVER (
PARTITION BY some_id, some_nm, some_description
ORDER BY some_id, some_nm, some_description )
FROM tbl_some_table
) tb_dup
WHERE tb_dup.dup_idx > 1; |
이것 또한 그냥 메모입니다. 하하.
출처 : https://withsoju.tistory.com/686